
Generating Unique Sound Samples Using Artificial Intelligence and Deep Learning
The rise of artificial intelligence has become undeniable due to the advancement of ChatGPT. However, few people know that this technology is not new. In its rudimentary form, it has existed for decades. With this technology, we can generate images, videos, and code from text. The music industry is also beginning to embrace the idea of utilizing this technology. Current music industry solutions mainly focus on generating new music and vocal sounds, while the generation of unheard new timbres is still somewhat neglected. We are engaged in creating VST software and sample-based software, so we have initiated an experimental project to experience the advantages and disadvantages of transformative technologies and try to determine how we can utilize this technology in the development of VST software.
Like every initial project, the system we created has its limitations, so we did not develop artificial intelligence for general tasks, but trained it exclusively for a specific task. This is the generation of new monophonic timbres based on a training dataset.
Our AI Bass Ultimate software contains generated bass guitar sounds. However, to create this, we needed an algorithm with deep learning capabilities and a high-quality audio sample set that contains a large number of bass guitar sound samples.
The average person might wonder why we create generated bass sounds when we already have high-quality bass guitar sound samples? If we think about how much time and energy we put into creating the sample sounds and developing the deep learning-based algorithm, our effort might seem unnecessary. However, focusing not on the present, the legitimacy of the solution becomes clear.
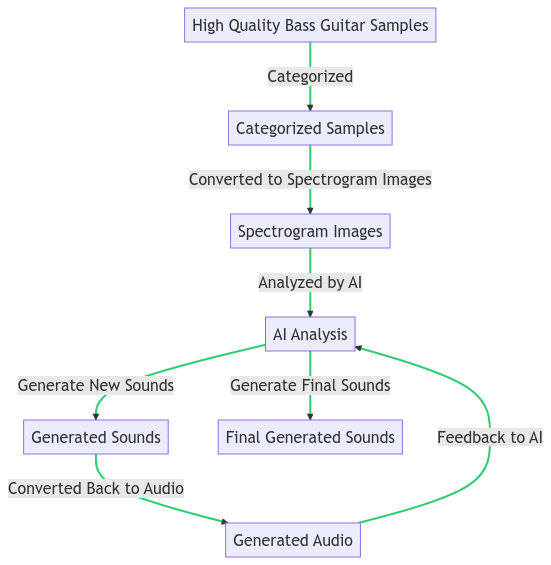
Technically, the following processes take place: We break down the large amount of excellent quality guitar audio material into different categories according to pitch, playing style, and sound difference. The files are 24-bit and 88.2 kHz quality. The bit depth was important to keep the noise level low. The high sampling frequency ultimately mattered less, but minimally contributed to perfecting the learning process. We transformed the categorized sounds into a format that the algorithm could interpret. That is, we delivered it for processing as a high-resolution spectrogram image.

A great advantage was that the sounds serving as samples were monophonic, so the characteristics of the individual sounds were much easier to detect for artificial intelligence. An average guitar sound plucking contains the fundamental tone and its harmonics. These are easily outlined on the spectrogram, the overlaps of individual sounds blur the appearance of individual frequencies much less than when analyzing a polyphonic sound.
After analyzing the images, the algorithm started generating the pitches we specified. We analyzed these created sounds and fed the better generated sounds back into the algorithm. When generating sounds, the AI first generated not a sound, but a spectrogram image which was then converted into sound material. So this technology differs from the OpenAI Jukebox technology, where much more complex solutions are needed. Our procedure would be best compared to training Midjourney or Stable Diffusion to create spectrograms, then converting the generated image into sound.
The legitimacy of the technology:
The next phase of training shows much more exciting perspectives. The AI can already differentiate between noisier and less noisy sound samples, thus it is able to generate good quality sound samples based on not particularly outstanding sound quality sample sounds. Furthermore, it increasingly needs less quantity of sample sounds. In the near future, we can create complex sample banks by feeding in a few samples. Since our algorithm also builds on morphing, we can also mix two different sound materials into a completely unique one. This way, we can play the sounds of new non-existent instruments that we have not heard before.The creation of entirely new instrument sounds currently encounters a significant obstacle. The issue is that digital signal processing for sound has matured over the years. Musicians have exhausted every existing method to create new sounds. As a result, any unique instrument sounds we've attempted to create with our technology are fundamentally achievable using already known methods. However, we remain optimistic, as the application of AI in audio technology is only just beginning to spread its wings. Given that it's a rapidly developing industry, we expect unique solutions to emerge soon.
